DATABASE
Database is an important constituent for collection and storage of data. Data provided information after processing on them. To managing record and important data Databases server used. Database transaction is a unit of work in database management system. Database transaction must follow term ACID (Atomicity, Consistency, Isolation, Durability). Any transaction started then till it completion, that transaction follow ACID, for successful and no error. The ability to modify the schema definition in one level should not affect the schema definition in the next higher level is called Data Independence. The application is independent of the storage structure and access strategy of data.
Two types of Data Independence are:
1. Logical Data Independence: It is more difficult to achieve. Modification in logical level should affect the view level.
2. Physical Data Independence: Modification in physical level should not affect the logical level.
ACID Property
Means atomicity, consistency, isolation and durability.
Atomicity: Each transaction is said to be “atomic". Means if any part of transaction fail then whole transaction failed. In a word say "ALL OR NOTHING". The failure of transaction commonly depend on Hard disk fail, System crash.
Consistency: Consistency means only valid data will be written to the database. If any transaction violate any consistency rule of database the whole transaction is Rollback, means it starts again from beginning. Each state in transaction must be consistent for database.
Isolation: If two transactions occurs at a time then both are not impact to each other, separate completion of each transaction. The isolation property does not ensure which transaction will execute first, merely that they will not interfere with each other. If second transaction depend on first then it will done, and data update after completion of traction.
Durability: Ensures that any transaction committed to the database will not be lost. Durability is ensured through the use of database backups and transaction logs that facilitate the restoration of committed transactions in spite of any subsequent software or hardware failures.
Atomicity: Each transaction is said to be “atomic". Means if any part of transaction fail then whole transaction failed. In a word say "ALL OR NOTHING". The failure of transaction commonly depend on Hard disk fail, System crash.
Consistency: Consistency means only valid data will be written to the database. If any transaction violate any consistency rule of database the whole transaction is Rollback, means it starts again from beginning. Each state in transaction must be consistent for database.
Isolation: If two transactions occurs at a time then both are not impact to each other, separate completion of each transaction. The isolation property does not ensure which transaction will execute first, merely that they will not interfere with each other. If second transaction depend on first then it will done, and data update after completion of traction.
Durability: Ensures that any transaction committed to the database will not be lost. Durability is ensured through the use of database backups and transaction logs that facilitate the restoration of committed transactions in spite of any subsequent software or hardware failures.
KEYS
A database key is a attribute utilized to sort and identify data in some manner.
There are many keys:
There are many keys:
1. Primary key: The primary key is a attribute of a relational table uniquely identifies the each tuple of a table or each record in the table. It can either be a normal attribute that is guaranteed to be unique. Such as Social Security Number in a table with no more than one record per person. Examples: Imagine we have a employees table that contains a record for each employee at a organization. The employee's unique employee ID number would be a good choice for a primary key in the employees table. The employee's first and last name would not be a good choice, as there is always the chance that more than one employee might have the same name.
2. Foreign Key: These keys are used to create relationships between tables. Natural relationships exist between tables in most database structures. Example: Let’s assume that the Departments table uses the Department Name column as the primary key. To create a relationship between the two tables, we add a new column to the Employees table called Department. We then fill in the name of the department to which each employee belongs. We also inform the database management system that the Department column in the Employees table is a foreign key that references the Departments table. The database will then enforce referential integrity by ensuring that all of the values in the Departments column of the Employees table have corresponding entries in the Departments table.
3. Candidate key, Alternate key and Composite key: Any number of attributes that are uniquely identifying a row in a table is “candidate key” for the table. We select one of the candidate key as Primary key. All candidate keys which are not chosen as "primary key" are “Alternate keys”. The key which uniquely identify the rows of the table and which is made up of more than one attribute is called “composite key”.
For Example: In a class we have to select Class Representative. So A, B, C and D stand for that post. So A, B, C and D are candidate for Class Representative so these are candidate key. We select B as Class Representative so B is primary key and A, C and D can be Class Representative but not selected as a Class Representative so they are alternative choice. So A, C and D are alternate key. When two students of class work together in a project then they are composite key for the class.
For Example: In a class we have to select Class Representative. So A, B, C and D stand for that post. So A, B, C and D are candidate for Class Representative so these are candidate key. We select B as Class Representative so B is primary key and A, C and D can be Class Representative but not selected as a Class Representative so they are alternative choice. So A, C and D are alternate key. When two students of class work together in a project then they are composite key for the class.
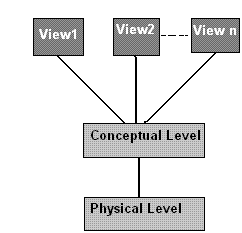
LEVELS OF ABSTRACTION
Physical Level: Physical level is the lower level of abstraction. Its define how data is stored in database.
Logical Level: The next higher level of abstraction, its describe what data be store and each logical operation done at this level, links and concept apply here.
View Level: This is the higher level describe only part of entire database for a particular user.
NORMALIZATION
Some rules that should followed to achieve a good database design are:
- Each table should have an identifier.
- Each table should store data for a single type entity
- Columns that should store data for a single type of entity.
- The repetition of values or columns should be avoided.
To remove the redundancy of a table as called Normalization. In other words duplicity or repetitions of data never occur in database. Normalization is mainly minimizing redundancy, insertion, deletion and update anomalies. Normalization achieve through functional dependency. Normalization is much type.
Functional Dependency: Functional dependencies (FDs) are used to specify formal measures of the "goodness" of relational designs and used to define normal forms for relations. FDs are constraints that are derived from the meaning and interrelationships of the data attributes. FDs are derived from the real-world constraints on the attributes
For example: A set of attributes X functionally determines a set of attributes Y if the value of X determines a unique value for Y
X-->Y holds if whenever two tuples have the same value for X, they must have the same value for Y If t1[X] =t2[X], then t1[Y] =t2[Y] in any relation instance r(R)
X-->Y in R specifies a constraint on all relation instances r(R)
For example: A set of attributes X functionally determines a set of attributes Y if the value of X determines a unique value for Y
X-->Y holds if whenever two tuples have the same value for X, they must have the same value for Y If t1[X] =t2[X], then t1[Y] =t2[Y] in any relation instance r(R)
X-->Y in R specifies a constraint on all relation instances r(R)
Fully Functional dependency: A functional dependency X --> Y is full functional dependency if any attribute A removed from X. It means that the dependency does not hold any more then it is not Fully Functional dependence. Means each attribute is functionally dependent.
All categories are in sequential order:
1.1NF: There is no repetition of values and data in table known as 1NF. In other words the 1NF disallows composite attributes, multivalued attributes, and nested relations, attributes whose values for an individual tuple are non-atomic.
2.2NF: A relation schema R is in 2NF when it is in 1NF and every non-prime attribute A in R is fully functionally dependent on primary key.
3.3NF: A relation schema R is in 3NF ,It is in 2NF and no non-prime attribute A in R is transitively dependent on the primary key. Transitive dependent means if there a set of attribute Z that are neither a primary or candidate key and both X-->Z and Y-->Z holds.
4.BCNF: 3NF inadequate in some situation then it was not satisfactory for the table:
- That had multiple candidate keys.
- Where the multiple candidate keys were composite.
- Where the multiple candidate keys were overlapped.
A relation schema R is in BCNF, It is in 3NF and additional constraints that for every FD X -> A, X must be a candidate key. "A relation is in the Boyce-Codd normal form (BCNF) if and only if every determinant is a candidate key "
5.4NF: A relation schema R is said to be in 4NF, it is in BCNF and for every Multivalued dependency X --> Y that holds over R, Either X is subset or equal to (or) XY = R. or X is a super key.
6.5NF: A relation schema R is said to be in 5 NF, it is in 4NF and relation schema R is said to be 5NF if for every join dependency {R1, R2, ..., Rn} that holds R, one the following is true Ri = R for some i. and The join dependency is implied by the set of FD, over R in which the left side is key of R.

Demoralization
The intentional introduction of redundancy in a table in order to improve performance is called demoralization. The decision to demoralize results in a trade-off performance and data integrity. Demoralization increases disk utilization.
OTHER DATABASE MODELS
Relational Database Model
Data represent in form of column and row, column means attribute and row means touples present instance of data. This Database model came into existence with help of mathematical concepts. Its using some other concepts like normalization, touple relational calculus.
E-R Model in Database
E-R model stands for Entity-Relationship model. This data model is based on real world that consists of basic objects called entities and of relationship among these objects. Entity in database, which existence in real world with number of attributes. In a table attribute know as column. Relationship is a logical thing which relates entities. The E-R diagram shows structure of E-R model.
Object Oriented Database Model
This model is based on collection of objects. An object is instance variables which store value and bodies of code, that codes are called method. These codes have written to operate the objects. Objects that contain same types of values and the same methods are grouped together into classes. In other words classes are a group of object. This model also follows the some concept related to the OOPs
Hierarchical model of Database
The word hierarchy means tree form relationship, like a tree with branches. Means Relationship formed like tree structure in a database called hierarchical model. With this database you form relationship among many tables with certain concept. It has a downward link to describe the nesting and they are arranged in a particular order down the same level of the list.
Network model
This model provides greater flexibility and easy access to data. This model provide logical relationship among many parent database. But implementing this model is more difficult due to time consuming and cost. Its flexible because through link easily accessing of information.
XML Database
XML databases came into existence in 2000. This database lets you organize data irrespective of whether it is organized or not. This data can exported and serialized into the desired format. Two major classes of XML database exist:
1. XML-enabled
2. Native XML
1. XML-enabled
2. Native XML
Codd's Twelve Rules
1. The information rule: This rule require all information to be represented as data values in the rows and column of table.
2. The guaranteed access rule: Every data value in a relational database should be logically accessible by specifying a combination of table name and column name.
3. Systematic treatment of NULL values: DBMS support NULL values ,in case when user leave the column in the table.
4. Active online catalog based on relational model: DBMS maintain system catalog. System catalog is a collection of system table.
5. The comprehensive data sublanguage rule: System must support following functions :
- Data definition
- View definition
- Data manipulation operation
- Security and integrity constraints
- Transaction management operation
6. The view update rule: All views that are theoretically updated must be updated by the system.
7. High level insert, update and delete: Means update at a time many rows values. Data are treated as set ,which are easily delete, update and insert.
8. Physical data independence: Application programs must remain unimpaired when any changes are made in storage representation or across methods.
9. Logical data independence: Changes should not affect the user's ability to work with the data.
10. Integrity independence: Integrity constraints must be storable in the system catalog.
11. Distribution independence: Database must allow manipulation of distributed data located on different computer system.
12. Nonsubversion rule: This rule state that different language bypass the integrity rule and constraints.
MS SQL Server
Fully Web Enabled
You can use HTTP to send queries to the server. It provides various feature and facility to accesses data on web.
Highly Scalable and Reliable
SQL sever use scale up and scale out feature to fulfill requirement . In Scale up SQl server use 32 bit Processors and 64GB of RAM to increase the load. In scale out SQL distribute database and data load across the server. When suddenly system crash ,RDBMS recover data quickly with minimum loss. This feature called reliability.
Client Server Architecture (Two Tier Architecture)

Data Sharing,
Reduce Duplication and maintenance
SQL
- Language to access data object from the SQL server
- Stands for Structured Query Language
- SQL addresses data in sets of rows and column rather than addressing individual component or a single data
- SQL support automatic navigation to target the data means user find data without knowing how to get this data and how to store the data
- Using this user never waste the time on representation of data, user only concentrate on logic
Data types
| Dtatype | Range | Used to store |
| int | -2^31 (-2,147,483,648) to 2^31 - 1 (2,147,483,647) | Integer data (whole numbers) |
| smallint | -2^15 (-32,768) to 2^15 - 1 (32,767) | Integer data |
| tinyint | 0 to 255 | Integer data |
| bigint | -2^63 (-9,223,372,036,854,775,808) to 2^63-1 (9,223,372,036,854,775,807) | Integer data |
| float | -1.79E + 308 to 1.79E + 308 | Floating precision data |
| money | -2^63 (-922,337,203,685,477.5808) to 2^63 - 1 (+922,337,203,685,477.5807) | Monetary data |
| smallmoney | -214,748.3648 to +214,748.3647 | Monetary data |
| datatime | January 1, 1753, to December 31, 9999 | Date and time data |
| smalldatatime | January 1, 1900, to June 6, 2079 | Date and time data |
| char(n) | n characters, where n can be 1 to 8000 | Fixed length character data |
| varchar(n) | n characters, where n can be 1 to 8000 | Variable length character data |
| text | Maximum length of 2^31 - 1 (2,147,483,647) characters | Character string |
| ntext | Maximum length of 2^30 - 1 (1,073,741,823) characters | Variable length Unicode data |
| bit | 1 or 0 value | Integer data with 0 or 1 |
| image | Maximum length of 2^31 - 1 (2,147,483,647) bytes | Variable length binary data to store images |
| real | -3.40E + 38 to -1.18E - 38 | Floating precision number |
| binary | Maximum length of 8,000 bytes | Fixed length binary data |
| varbinary | Maximum length of 8,000 bytes | Variable length binary data |
| nchar | Maximum length of 4,000 characters | Fixed length Unicode data |
| nvarchar | Maximum length of 4,000 characters | Variable length Unicode data |
| sql_varient | Maximum storage size of8016 bytes | Contain rows of different datatypes except text, ntext, image, timestamp and sql_variant |
| timestamp | Maximum storage size of 8 bytes | unique number in a database that get updated every time a row that contains it is inserted or updated |
SQL Server
DDL (Data Definition Language)
Data Definition Language (DDL) statements are used to define the database structure or schema. DDL statements are used to build and modify the structure of your tables and other objects in the database. When you execute a DDL statement, it takes effect immediately.
1. CREATE: To create objects in the database
CREATE TABLE <table_name> ( <attribute_name 1> <data_type 1>,
...
<attribute_name n> <data_type n>);
...
<attribute_name n> <data_type n>);
2. ALTER: Alters the structure of the database
ALTER TABLE <table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY (<attribute_list>);
ADD CONSTRAINT <constraint_name> PRIMARY KEY (<attribute_list>);
The foreign key constraint is a bit more complicated, since we have to specify both the Foreign Key attributes in this (child) table, and the Primary Key attributes that they link to in the parent table.
ALTER TABLE <table_name>
ADD CONSTRAINT <constraint_name> FOREIGN KEY (<attribute_list>)
REFERENCES <parent_table_name> (<attribute_list>);
ADD CONSTRAINT <constraint_name> FOREIGN KEY (<attribute_list>)
REFERENCES <parent_table_name> (<attribute_list>);
3. DROP: Delete objects from the database
DROP TABLE <table_name>;
ALTER TABLE <table_name>
DROP CONSTRAINT <constraint name>;
ALTER TABLE <table_name>
DROP CONSTRAINT <constraint name>;
4. TRUNCATE: Remove all records from a table, including all spaces allocated for the records are removed
5. COMMENT: Comments added to the data dictionary.
6. RENAME: Rename an object of the Database.
DML (Data manipulation language)
.DML statements are used to work with the data in tables. SELECT, INSERT, UPDATE, DELETE statements are consider as a DML statement.
1. SELECT: SQL server provide the SELECT statement to retrieve data from database. The keywords SELECT, FROM and WHERE makeup the basic SELECT statement . SELECT statement promote the server to querying single table or multiple tables in Database and prepare a result and return to the client application.
Selecting Columns
The column name from a table specified in the SELECT statement separated by a comma (,) and there is no need to insert a comma after the last column name.
SELECT column_name 1,column_name 2....column_name n
FROM table_name
FROM table_name
The above query retrieve the column data which you pass in the query from table which you pass after From keyword.
Selecting All Columns
The SELECT statement used with an asterisk (*) symbol to display all column of the table
SELECT *
FROM table_name
FROM table_name
2. INSERT: The insert statement is used to add new rows to a table. There will need a separate INSERT statement for every row. The statement of Insert will be:
INSERT INTO table_name
VALUES (value 1, ... value n);
INSERT INTO table_name
VALUES (value 1, ... value n);
- The number of attributes and the data type of each attribute
- Character type values are always enclosed in single quotes
- Number values are never in quotes
- Date values are often in the format 'yyyy-mm-dd' (for example, '2010-12-24')
3. UPDATE: The update statement is used to change values that are already in a table.
UPDATE table_name
SET attribute_name 1 = value 1, attribute_name 2 = value 2....attribute_name n = value n
WHERE condition;
UPDATE table_name
SET attribute_name 1 = value 1, attribute_name 2 = value 2....attribute_name n = value n
WHERE condition;
- If the WHERE clause is omitted, then the specified attribute is set to the same value in every row of the table
- Set multiple attribute values at the same time with a comma-delimited list of attribute_name=value pair
4. DELETE: The delete statement does just that, for rows in a table.
DELETE FROM table_name
WHERE condition; If the WHERE clause is omitted, then every row of the table is deleted
DELETE FROM table_name
WHERE condition; If the WHERE clause is omitted, then every row of the table is deleted
5. CALL: Call a PL/SQL
6. EXPLAIN PLAN: Explain access path to data
7. LOCK TABLE: Control concurrency
DCL (Data Control Language)
- DCL stands for Data Control Language
- Used to create roles
- Used to create permissions
1. GRANT: Gives user to access database means user privilege to database.
2. REVOKE: Withdraw access privileges given with the GRANT command
TCL (Transactional Control Language)
- TCL is stands for Transactional Control Language
- It is used to manage different transactions occurring within a database
1. COMMIT: This Statement used to save work done by the user. 2. SAVEPOINT: Identify the point which you can later roll back in a transaction.
3. ROLLBACK: Restore database to original.
4. SET TRANSACTION: Change transaction options like isolation level and what rollback segment to use
Using Logical Operator
Multiple search condition done by using logical operator. They are:
1. OR: Any of the specified search condition is true.
SELECT column_list
FROM table_name
WHERE condition_expression OR condition_expression
FROM table_name
WHERE condition_expression OR condition_expression
Return all rows specific to the conditions, even if any one of the condition is true.
2. AND: When all specified search conditions are true.
SELECT column_list
FROM table_name
WHERE condition_expression AND condition_expression
FROM table_name
WHERE condition_expression AND condition_expression
Return all rows specific to the conditions, when both conditions are true.
3. NOT: Neutralizes the expression that follow it.
SELECT column_list
FROM table_name
WHERE condition_expression {OR/AND} NOT condition_expression
FROM table_name
WHERE condition_expression {OR/AND} NOT condition_expression
Return all rows specific to the conditions, except the rows that match the condition specified after the NOT operatoor.
Using List Operator
SQl provides IN and NOT IN operators. IN operator that allowed the selection of values that match any one of the values in a list. NOT IN operator restrict the selection of values that match any one of the values in a list.
SELECT column_list
FROM table_name
WHERE condition list_operator('value_list')
FROM table_name
WHERE condition list_operator('value_list')
list_operator is any valid list operator.
value_list is the list of values to be included or excluded in the condition
For Example:
SELECT *
FROM publishers
WHERE state IN ('MA','DC')
FROM publishers
WHERE state IN ('MA','DC')
SELECT *
FROM publishers
WHERE state NOT IN ('MA','DC')
FROM publishers
WHERE state NOT IN ('MA','DC')
Using Comparison Operators
Comparison operator allow row retrieval from a table based on the condition specified in the WHERE clause.
SELECT column_list
FROM table_name
WHERE expression1 comparison_operator expression2
FROM table_name
WHERE expression1 comparison_operator expression2
Operator
|
Description
|
| = | Equal to |
| > | Greater than |
| < | Less than |
| >= | Greater than or equal to |
| <= | Less than or equal to |
| <>,!= | Not equal to |
| !> | Not greater than |
| !< | Not less than |
| () | Controls precedence |
For Example:
SELECT pub_id
FROM publishers
WHERE city='Boston'
FROM publishers
WHERE city='Boston'
Using Range Operators
The range operator is used to retrieve data between range . The range operator are:
1. BETWEEN: Specified an inclusive range to search.
SELECT column_list
FROM table_name
WHERE expression1 BETWEEN expression1 AND expression1
FROM table_name
WHERE expression1 BETWEEN expression1 AND expression1
For Example: Below query return the attribute list value between 2000 and 5000
SELECT *
FROM titles
WHERE advance BETWEEN 2000 AND 5000
FROM titles
WHERE advance BETWEEN 2000 AND 5000
2. NOT BETWEEN: This key word used to exclude the rows from the specified range in the result set.
SELECT column_list
FROM table_name
WHERE expression1 NOT BETWEEN expression1 AND expression1
FROM table_name
WHERE expression1 NOT BETWEEN expression1 AND expression1
For Example: Below query return the attribute list value which not between 2000 and 5000
SELECT *
FROM titles
WHERE advance NOT BETWEEN 2000 AND 5000
FROM titles
WHERE advance NOT BETWEEN 2000 AND 5000
Using String Operator
String operator provide a LIKE keyword to search for a string with wild card mechanism.
Wildcard
|
Description
|
| % | Represents any string of Zero or more character |
| _ | Represent the single character |
| [] | Represent any single character within the specified range |
| [^] | Represent any single character not within the specified range |
For Example:
SELECT *
FROM titles
WHERE type LIKE 'bus%'
FROM titles
WHERE type LIKE 'bus%'
Return all attribute from the titles table in which the type starts with 'bus'
SELECT *
FROM titles
WHERE type LIKE 'bu_'
FROM titles
WHERE type LIKE 'bu_'
Return all attribute from the titles table in which the type of book is the three character long and starts with 'bu'. Increase the '_' keyword increase the number of characters.
SELECT *
FROM titles
WHERE type LIKE 'b[us]%'
FROM titles
WHERE type LIKE 'b[us]%'
Return all attribute from the titles table in which the type of book is starts with 'b' and contain u and s on the second position followed by any number of character.
SELECT *
FROM titles
WHERE type LIKE 'b[^s]%'
FROM titles
WHERE type LIKE 'b[^s]%'
Return all attribute from the titles table in which the type of book is starts with 'b' and does not contain s on the second position followed by any number of character.
Some Examples
Expression
|
Returns
|
| LIKE '%ty%' | All names that have the letters 'ty' in them |
| LIKE '_ty' | All three letter names ending with 'ty' |
| LIKE '[AD]%' | All name that begin with "A" or "K" |
Using IS NULL & IS NOT NULL
In SQL server, NULL is a unknown value means the data is not available. The NULL can be retrieve from the table using IS NULL keyword in the WHERE clause.
Note: NO two NULL values are equal. You can not compare one NULL value to other.
SELECT column_list
FROM table_name
WHERE column_name unknown_value_operator
FROM table_name
WHERE column_name unknown_value_operator
Where unknown_value_operator is either the keyword IS NULL or IS NOT NULL.
Example:
SELECT *
FROM publishers
WHERE state IS NULL
FROM publishers
WHERE state IS NULL
Returns the all attributes of publisher table where state attribute contain NULL
SELECT *
FROM publishers
WHERE state IS NOT NULL
FROM publishers
WHERE state IS NOT NULL
Returns the all attributes of publisher table where state attribute does not contain NULL
Using ORDER BY Clause
It retrieve and display the data in specific order. ASC is the default sort order.
SELECT column_list
FROM table_name
ORDER BY column_name ASC/DESC
FROM table_name
ORDER BY column_name ASC/DESC
For Example:
SELECT *
FROM publishers
ORDER BY pub_name DESC
FROM publishers
ORDER BY pub_name DESC
Return all attributes of publishers able in order to descending alphabetically order with respect to pub_name attribute
Using TOP keyword
The TOP clause used with the SELECT statement. It is used to limits the number of rows returned in the result set
SELECT [TOP n] column_mame
FROM table_name
WHERE search_conditions
FROM table_name
WHERE search_conditions
'n'=number of rows that you want to retrieve.
For Example:
SELECT TOP 5 pub_id,pub_name,country
FROM publishers
WHERE country LIKE 'U%'
ORDER BY pub_id DESC
FROM publishers
WHERE country LIKE 'U%'
ORDER BY pub_id DESC
Returns all top 5 rows ,pub_id, pub_name and country, from the publishers table in descending order with respect to pub_id.
Using DISTINCT keyword
It also used to limit the result set. The DISTINCT keyword remove the duplicate row from the returned result set. It used with the SELECT statement.
SELECT DISTINCT column_mame
FROM table_name
WHERE search_conditions
FROM table_name
WHERE search_conditions
For Example:
SELECT DISTINCT country
FROM publishers
WHERE city LIKE 'B%'
FROM publishers
WHERE city LIKE 'B%'
Return country name which started with a 'B' alphabet but no repetition, means no duplicate value of country.
Using Aggregate Functions
These function are specially executed for the mathematical expression.
Function Name
|
Parameters
|
Description
|
AVG
| (ALL, DISTINCT Expression) | Return the average of value in a numeric expression |
COUNT
| (ALL, DISTINCT Expression) | Return the number of values in an expression |
COUNT
|
(*)
| Returns the no. of rows returned by the query |
MAX
|
(expression)
| Return the highest value in the expression |
MIN
|
(expression)
| Return the lowest value in the expression |
SUM
|
(ALL, DISTINCT Expression)
| Return the total of value in a numeric expression |
The AVG, COUNT, MAX, MIN and SUM function ignore NULL values, whereas the COUNT (*) function counts the NULL values.
Examples
|
Description
|
| SELECT 'avg'=AVG (discount) FROM discounts | Returns the average value of the discount |
| SELECT 'sum'=SUM (discount) FROM discounts | Returns the sum value of the discount |
| SELECT 'min'=MIN (discount) FROM discounts | Returns the minimum value of the discount in discounts table |
| SELECT 'max'=MAX (discount) FROM discounts | Returns the maximum value of the discount in discounts table |
| SELECT 'count'=COUNT (discount) FROM discounts | Return the number of discount value in discounts table |
Using GROUP BY Clause
Group clause summarize the result set in to a groups defined in the query using aggregate function.
SELECT column1, column2, ... column_n, aggregate_function (expression)
FROM table_name
WHERE conditions
GROUP BY ALL column1, column2, ... column_n
FROM table_name
WHERE conditions
GROUP BY ALL column1, column2, ... column_n
expressions describe the column name (s) or expressions on which the result set of the SELECT statement is to be grouped.
ALL is a keyword used to include those groups that do not meet the search condition.
For Example:
SELECT type, 'avg'=AVG(advance)
FROM titles
WHERE type LIKE 'b%'
GROUP BY ALL type
FROM titles
WHERE type LIKE 'b%'
GROUP BY ALL type
Out Put
type avg
-----------------------------------------------
business 5000.0000
mod_cook NULL
popular_comp NULL
psychology NULL
trad_cook NULL
UNDECIDED NULL
-----------------------------------------------
business 5000.0000
mod_cook NULL
popular_comp NULL
psychology NULL
trad_cook NULL
UNDECIDED NULL
Return all type from table but the 'avg' display only those type which started with ' b'. Means this keyword used to display all groups, including those exclude from WHERE clause. The ALL keyword is meaningful for those query that contain WHERE clause.
For Example:
SELECT type,'pub Id'=pub_id, 'avg'=AVG (price)
FROM titles
GROUP BY type,pub_id
FROM titles
GROUP BY type,pub_id
Return the 'type' and 'pub Id' and 'avg' , which calculated from titles table.
For Example:
SELECT type, 'avg'=AVG(advance)
FROM titles
WHERE title_id IN ('BU1032','PC1035')
GROUP BY ALL type
FROM titles
WHERE title_id IN ('BU1032','PC1035')
GROUP BY ALL type
Out Put
type avg
-----------------------------------------------
business 5000.0000
mod_cook NULL
popular_comp 7000.0000
psychology NULL
trad_cook NULL
UNDECIDED NULL
-----------------------------------------------
business 5000.0000
mod_cook NULL
popular_comp 7000.0000
psychology NULL
trad_cook NULL
UNDECIDED NULL
Using compute Clause
- Used to generate summary rows using aggregate function in the query results.
- COMPUTE BY clause can be used to calculate summary values of the result set on a group of data.
- The main difference between GROUP BY and COMPUTE BY Clause is, GROUP BY Clause is used to generate a group summary report and does not produce individual table rows in the result set whereas COMPUTE BY Clause generate the summary report with individual data rows from the table.
SELECT column_name
FROM table_name
ORDER BY column_name
COMPUTE aggregate_function (column_name) BY column_name 1...column_name n
FROM table_name
ORDER BY column_name
COMPUTE aggregate_function (column_name) BY column_name 1...column_name n
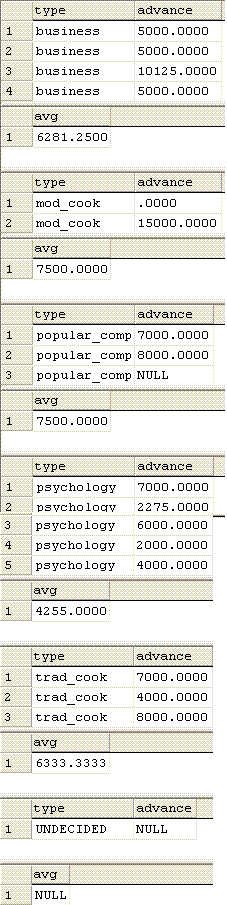
For Example:
SELECT type, advance
FROM titles
ORDER BY type
COMPUTE AVG (advance) BY type
FROM titles
ORDER BY type
COMPUTE AVG (advance) BY type
Out Put
Some points regarding the use of the COMPUTE and COMPUTE BY
- The DISTINCT keyword cannot be used with the aggregate function
- All columns referred to in the COMPUTE clause must appear in the select column list
- The ORDER BY Clause must be used whenever the COMPUTE BY Clause is used
- The ORDER BY Clause can be eliminate only when the COMPUTE BY Clause is used
- The column listed in the COMPUTE BY Clause must match the columns used in the ORDER BY Clause
- More than one COMPUTE clause can be used in the SELECT statement to produce a result with subtotals and grand total
- The different aggregate function can be used on more than one column with the COMPUTE BY Clause
- More than one column or expression can be specified after the COMPUTE BY clause. The order of columns or expression used in the COMPUTE BY clause must match the order of columns or expression specified in the ORDER BY Clause.
Using String Functions
This function use to format data that will meet specific requirements. Mostly they are used with the char and varchar data types. It used for implicit convert data to char to varchar.
SELECT function_name (parameter)
function_name is the name of the string function. parameter are required parameters for the string function.
Function name
|
Parameters
|
Example
|
Description
|
ASCII
| (character_expression) | SELECT ASCII ('ADI') | Return 65 the ASCII code of the leftmost character 'A' |
CHAR
| (integer_expression) | SELECT CHAR (65) | Return A the character equivalent of the ASCII code value |
CHARINDEX
| ('pattern', expression) | SELECT CHARINDEX ('O','HELLO') | Returns 5, the standing position of the specified pattern in the expression |
SOUNDEX
| (character_expression) | SELECT SOUNDEX ('ADITYA') | Return the four character code to compare the string |
DIFFERENCE
| (character_expression1, character_expression2) | SELECT DIFFERENCE ('ADITYA','ADI') | Difference function compare the SOUNDEX value of two string and return a value from 0 to 4. The value 4 is best match. |
LEFT
| (character_expression, integer_expression) | SELECT LEFT ('ADITYA','4') | Return 'ADIT', which is the part of character string equal in size to the integer_expression character from the left |
LEN
| (character_expression) | SELECT LEN ('ADITYA') | Return 6, the no of character in the (character_expression) |
LOWER
| (character_expression) | SELECT LOWER ('ADITYA') | Return 'aditya', after the converting (character_expression) to the lower case |
LTRIM
| (character_expression) | SELECT LTRIM (' ADITYA') | Return 'ADITYA' without leading spaces. It removes leading blanks from the character expression |
PATINDEX
| ("%pattern%, expression") | SELECT PATINDEX ('%TY%','ADITYA') | Return 4, the standing position of the first occurrence of the pattern in the specified expression, or zero if pattern is not found |
REVERSE
| (character_expression) | SELECT REVERSE ('ADITYA') | Return 'AYTIDA' , the reverse of the (character_expression) |
RIGHT
| (character_expression, integer_expression) | SELECT RIGHT ('ADITYA',4) | Return 'ITYA' , the part of the character string. |
RTRIM
| (character_expression) | SELECT LTRIM ('ADITYA ') | Return 'ADITYA' without leading spaces. It removes leading blanks from the character expression |
SPACE
| (integer_expression) | SELECT 'ADITYA'+SPACE(2)+'TIWARI' | Returns 'ADITYA TIWARI'. Two space are inserted between the first and second word |
STR
| (float_expression, [length,[decimal]]) | SELECT STR (123.45,6,2) | Return '123.45'. It converts numeric data to character data where the length is the total length ,including the decimal point, the sign, the digits, the spaces and the decimal is the number of places to the right of the decimal point |
STUFF
| (character_expression1, start, length, character_expression2) | SELECT STUFF ('Aditya',2,3,'s') | Return 'Asya'. It delete length characters from character_expression1 from the start and then inserts character_expression2 into character_expression1 at the start position |
SUBSTRING
| (expression, start, length) | SELECT SUBSTRING ('Aditya',2,3) | Returns 'dit', which is part of a character string. It returns length character from the start position of the expression |
UPPER
| (character_expression) | SELECT UPPER ('aditya') | Return 'ADITYA', after the converting (character_expression) to the upper case |
Using DATE Functions
Date function of SQL is:
- Used to manipulate date time values
- Perform arithmetic operations
- Perform date parsing
- Add two date or subtract one date from another
SELECT date_function (parameters)
date_function is the name of date function
parameters are the required parameters of the date function
Function Name
|
Parameter
|
Description
|
| DATEADD | (datepart,number,date) | Adds the number of dateparts to the date |
| DATEDIFF | (datepart,date1,date2) | Calculates the number of dateparts between two dates |
| DATENAME | (datepart,date) | Return datepart from the listed date, as character value (for example: March) |
| DATEPART | (datepart,date) | Returns datepart from the listed date as an integer |
| GETDATE | () | Returns current date and time |
For Example:
SELECT getdate()
The above statement display the current system date by using getdate() function.
SELECT 'getdate'= DATEADD(yy,2,pubdate)
FROM titles
FROM titles

Return the all pubdate from titles table with increment of 2 in each year of the table.
SELECT datepart (yy,pubdate)
FROM titles
FROM titles

Return all Date from pubdate of titles table.
Using Mathematical Functions
Mathematical function perform numerical operation on mathematical data. The various mathematical functions are:
Function Name
|
Parameter
|
Description
|
ABS
| (numeric_expression) | Return an absolute value |
| ACOS,ASIN, ATN | (float_expression) | Returns the angle in radians whose cosin,sin and tangent is a floating point value |
| COS,SIN,COT,TAN | (float_expression) | Returns the angle in radians whose cosin, sin, tangent and cot of the angle |
DEGREES
| (numeric_expression) | Returns the smallest integer greater than or equal to the specified value |
EXP
| (float_expression) | Return the exponential value of the specified value |
FLOOR
| (numeric_expression) | Return the largest integer less than or equal to the specified value. |
LOG
| (float_expression) | Return the natural logarithm of the specified value |
LOG10
| (float_expression) | Return the base-10 logarithm of the specified value |
PI
| () | Returns the constant value of 3.141592653589793 |
POWER
| (numeric_expression, y) | Return the value of numeric_expression to the value of y |
RADIANS
| (numeric_expression) | Convert from degrees to radians |
RAND
| ([seed]) | Return a random float number between 0 and 1 |
ROUND
| (numeric_expression, length) | returns a numeric expression rounded off to the length specified as an integer expression |
SIGN
| (numeric_expression) | Returns positive, negative or zero |
SQRT
| (float_expression) | Return the square root of the specified value |
ROUND (numeric_expression,length)
numeric_expression is the numeric expression to be round off
SELECT 'value'= ROUND (123.452352,3)
Out Put:

Using System Functions
System function provide a method of querying the system tables of SQL server.
Function
|
Definition
|
HOST_ID()
| Returns the current host process ID number of a client process |
HOST_NAME()
| Return the current host computer name of a client process |
SUSER_SID(['login_name'])
| Return the user's login name corresponding to the user's security identification number |
USER_ID(['name_in_db'])
| Return the database identification number corresponding to the username |
USER_NAME(['user_id'])
| Return the user name corresponding to the database identification number |
DB_ID (['db_name'])
| Return the database ID number of the database |
DB_NAME(['db_id'])
| Returns the database name |
OBJECT_ID ('objname')
| Returns the database object ID number |
OBJECT_NAME('object_id')
| Returns the database object name |
JOINS
SQL server provide:
- A method to retrieving a data from more than one table using join at a time
- Implemented using SELECT statement, in which the SELECT statement contain the name of columns to be retrieve from the tables
- The FROM clause contains the name of the tables from which combined data is to be retrieved
- The WHERE specifies the rows to be included in the result set with the help of the join operator
Syntax:
SELECT column name 1, column name 2....column_name n
FROM table name [CROSS, INNER, OUTER] JOIN table_name
ON [table_name.ref_column_name] join_operator [table_name.ref_column_name]
WHERE search_condition
FROM table name [CROSS, INNER, OUTER] JOIN table_name
ON [table_name.ref_column_name] join_operator [table_name.ref_column_name]
WHERE search_condition
column_name specifies the name of the columns from one or more than one table that has to be displayed.
table_name specifies the name of the tables from which data to be retrieve.
ref_column_name specifies the name of the columns that are used to combined the two tables using the common keys from the respective tables.
join_operator specifies the operator used to join the tables
When two tables are joined, they must share a common key that defines how the rows in the tables correspond to each other. A primary key is validated against the foreign key when a joined is used.
Whenever a column is referred to in a join condition, it should be referred to either by prefixing it with the table name to which it belongs or by a table alias.
Table Alias: A table alias is required whenever an ambiguity is possible due to duplicate column names in a multiple tables A tables alias is a keyword defined in the FROM clause of the SELECT statement to uniquely identify the table.
Syntax:
FROM table_name table_alias
Where,
table_name specifies the name of the tables that have to be combined in the query
table_alias is the keyword used to refer to a table. It must follow the rules of identifiers
Types of JOIN
Inner Join
Outer Join
Cross Join
Equi Join
Natural Join
Self Join
Inner Join
In inner joining, data from multiple tables is displayed after comparing values present in a common column. Only rows with values satisfying the join condition column are displayed. Rows in both tables that do not satisfy the join condition are not displayed.
SELECT columnm_name
FROM table_name JOIN table_name
ON [table_name.ref_column_name] join_operator [table_name.ref_column_name]
FROM table_name JOIN table_name
ON [table_name.ref_column_name] join_operator [table_name.ref_column_name]
For Example:
SELECT title, royaltyper, royalty
FROM titleauthor JOIN titles
FROM titleauthor JOIN titles
ON titleauthor.title_id=titles.title_id
Return all title, royaltyper, royalty from table in which these attributes are present

Outer Join
An outer join displays NULL for the columns of the related table where it does not find matching records
- When the result set contains all rows from one table
- The matching rows from other
SELECT columnm_name 1, columnm_name 2....columnm_name n
FROM table_name [LEFT,RIGHT] OUTER JOIN table_name
ON [table_name.ref_column_name] join_operator [table_name.ref_column_name]
FROM table_name [LEFT,RIGHT] OUTER JOIN table_name
ON [table_name.ref_column_name] join_operator [table_name.ref_column_name]
Left Outer Join: Left outer join ensure the inclusion of rows the first table and the matching rows from the second table.
SELECT logo,price,notes
FROM pub_info p LEFT OUTER JOIN titles t
ON p.pub_id=t.pub_id
FROM pub_info p LEFT OUTER JOIN titles t
ON p.pub_id=t.pub_id

Right Outer Join: Right outer join ensure the inclusion of rows the second table and the matching rows from the first table.
SELECT logo,price,notes
FROM pub_info p RIGHT OUTER JOIN titles t
ON p.pub_id=t.pub_id
FROM pub_info p RIGHT OUTER JOIN titles t
ON p.pub_id=t.pub_id

Cross Join
- A join that included more than one table using keyword CROSS is called cross join
- The output of a such type of join is called Cartesian product
- In cross join each row of first table is joined to with the each row of second table
- The number of rows in the result set is the multiple of the first table rows and second table rows
SELECT column_name 1, column_name 2....column_name n
FROM table_name CROSS JOIN table_name
FROM table_name CROSS JOIN table_name
For example:
SELECT *
FROM sales CROSS JOIN publishers
FROM sales CROSS JOIN publishers

returns 168 rows, after cross join 21 rows of sales table and 8 rows of publishers tables
Equi Join
A equi join display redundant column of data in the result set, where two or more tables are compared for equality.
For Example:
SELECT *
FROM sales s JOIN titles t
ON s.title_id=t.title_id
JOIN publishers p
ON t.pub_id=p.pub_id
FROM sales s JOIN titles t
ON s.title_id=t.title_id
JOIN publishers p
ON t.pub_id=p.pub_id
Returns the above columns in the result set.
Natural Join
A join that restrict the redundant column from the result set is known as natural join
SELECT t.title, p.pub_name
FROM titles t JOIN publishers p
ON t.pub_id=p.pub_id
FROM titles t JOIN publishers p
ON t.pub_id=p.pub_id
Returns the all title and pub_name from respective tables.
Self Join
A join is said to self join when one row in a table correlates with the other rows in the same table. An alias name can differentiate the two copy of the table. All join operators except the outer join operators can be used in a self join.
For Example:
SELECT t1.title, t2.title, t1.price
FROM titles t1 JOIN titles t2 ON t1.price=t2.price
WHERE t1.price=2.99
FROM titles t1 JOIN titles t2 ON t1.price=t2.price
WHERE t1.price=2.99

Using EXITS Clause
A sub query used with the EXISTS clause, always returns data in terms of a TRUE or FALSE value. It checks for the existence of a data rows according to the condition specified in the inner query and passes the existence status to the outer query to produce the result set.
For Example:
SELECT pub_name
FROM publishers
WHERE EXISTS (SELECT * FROM titles WHERE type='business')
FROM publishers
WHERE EXISTS (SELECT * FROM titles WHERE type='business')
Out Put

Display the name of publishers who publish business related books.
SELECT title
FROM titles
WHERE advance > (SELECT avg(advance) FROM titles WHERE type='business')
Out Put

Display the titles of all those books for which the advance amount is greater than the average advance for bussiness related books.
Queries with modified Comparison Operators
SQL server provides the ALL and ANY keywords that can be used to modify the existing comparison operator. The sub query introduced with a modified comparison operator returns zero or more values and can be implemented using the GROUP BY or HAVING clause.
Operator
|
Description
|
>ALL
|
Means greater than the maximum value in the list.
column_name>ALL (10,20,30) means 'greater than 30'
|
>ANY
| Means greater than the minimum value in the list. column_name>ANY (10,20,30) means 'greater than 10' |
=ANY
| Means any of the values in the list. It acts in the same way as the IN clausecolumn_name=ANY (10,20,30) means 'equal to either 10 or 20 or 30' |
<>ANY
| Means not equal to any in the list. column_name<>ANY (10,20,30) means 'not equal to either 10 or 20 or 30' |
<>ALL
| Means not equal to all the values in the list. It acts in the same way as the NOT IN clause.column_name<>ALL (10,20,30) means 'not equal to either 10 and 20 and 30' |
For Example:
SELECT title_id ,title
FROM titles
WHERE price> ALL (SELECT price FROM titles WHERE pub_id='0736')
FROM titles
WHERE price> ALL (SELECT price FROM titles WHERE pub_id='0736')
Out Put:

Display the title_id and title where price is greater than the maximum price of books published by the publisher with the publisher ID 0736
SELECT title_id ,title
FROM titles
WHERE price>ANY(SELECT price FROM titles WHERE pub_id='0736')
FROM titles
WHERE price>ANY(SELECT price FROM titles WHERE pub_id='0736')

Display the title_id and title where price is greater than the minimum price of books published by the publisher with the publisher ID 0736
Extracting Data Into Another Table
A SELECT statement with the INTO clause is used to store the result set in a new table without a data definition process. The SELECT INTO statement creates a new table.
If the table is already exists, then the operation fails.
The command syntax is the,
SELECT columns_list
INTO new_table_name
FROM table_name 1, table_name 2.. table_name n
WHERE condition 1, condition 2..condition n
INTO new_table_name
FROM table_name 1, table_name 2.. table_name n
WHERE condition 1, condition 2..condition n
Where coloumn_list is the list of columns to be included in the new table.
new_table_name is the name of the new table where data is to be stored.
condition is the conditions on which rows are to be included in the new table.
For Example:
Create a new table from the title table.
SELECT title_id ,title
INTO aditya
FROM titles
WHERE price>15
INTO aditya
FROM titles
WHERE price>15
(8 row(s) affected)
SELECT *
FROM aditya
FROM aditya

A new table created named aditya
Using UNION Operator
SQL server provide a unique operator known as the UNION operator that is used to combine the result set of two or more queries.
SELECT column_list [ INTO new_table_name]
[FROM clause]
[WHERE clause]
[GROUP BY clause]
[HAVING clause]..]
UNION [ALL]
SELECT column_list
[FROM clause]
[WHERE clause]
[GROUP BY clause]
[HAVING clause]..]
[ORDER BY clause]
[COMPUTE BY clause]
[FROM clause]
[WHERE clause]
[GROUP BY clause]
[HAVING clause]..]
UNION [ALL]
SELECT column_list
[FROM clause]
[WHERE clause]
[GROUP BY clause]
[HAVING clause]..]
[ORDER BY clause]
[COMPUTE BY clause]
UNION ALL is the operator used to combine two or more queries with duplicate rows from different queries.
For Example:
SELECT au_fname,city,state
FROM authors
WHERE state='UT'
UNION
SELECT pub_name,city,state
FROM publishers
FROM authors
WHERE state='UT'
UNION
SELECT pub_name,city,state
FROM publishers
Out Put:

How to create a Data Base in SQL server
The creation of a database involves the database and determining the size of the database and the files used to store data in the database.
CREATE DATABASE database_name
ON
[<filespace>...n]
[<filegroup>...n]
LOG ON
(NAME=logical_file_name,
FILENAME='os_file_name',
SIZE=size,
MAXSIZE=max_size,
FILEGROWTH=growth_increment)
ON
[<filespace>...n]
[<filegroup>...n]
LOG ON
(NAME=logical_file_name,
FILENAME='os_file_name',
SIZE=size,
MAXSIZE=max_size,
FILEGROWTH=growth_increment)
where, data_base name is the name of new database.
ON specifies the disk files used to store the data portion of the database.
NAME=logical_file_name specifies the logical name for the file.
FILENAME=os_file_name specifies the operating system file name.
SIZE=size specifies the initial size f the file defined in the (<filespace>) list.
MAXSIZE=max_size specifies the maximum size to which the file defined in the <filespace> list can grow.
FILEGROWTH=growth_incremet specifies the growth increament of the file defined in the <filespace> list.
FILEGROUP filegroup_name name specifies the name of the filegroup.
LOG ON specifies the disk files used to store the log files.
For Example:
CREATE DATABASE aditya
ON
(NAME=aditya_dat,
FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL\DATA\aditya.mdf',
SIZE=12,
MAXSIZE=100,
FILEGROWTH=2)
LOG ON
(NAME='aditya_log',
FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL\DATA\aditya.ldf',
SIZE=4 MB,
MAXSIZE=50 MB,
FILEGROWTH=2 MB)
ON
(NAME=aditya_dat,
FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL\DATA\aditya.mdf',
SIZE=12,
MAXSIZE=100,
FILEGROWTH=2)
LOG ON
(NAME='aditya_log',
FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL\DATA\aditya.ldf',
SIZE=4 MB,
MAXSIZE=50 MB,
FILEGROWTH=2 MB)
Out Put:
The CREATE DATABASE process is allocating 12.00 MB on disk 'aditya_dat'.
The CREATE DATABASE process is allocating 4.00 MB on disk 'aditya_log'.
The CREATE DATABASE process is allocating 4.00 MB on disk 'aditya_log'.

Aditya named database created
.mdf, .ndf and .ldf EXTENSIONS FILES
.mdf Extension
- When we create a database, the CREATE command create a data file with extension .mdf is a primary file.
- It is a SQL Data files where all the data in the database objects are stored in
- Like tables, stored procedures, views, triggers etc. All are stored in the .mdf file of sql server
- This is the reason whey we use .MDF file to attaché the database. Once we attach the .mdf we were able to see all the data exist in that respective database.
..ldf Extension
- .ldf is the log file in the SQL server to see the data
- Transaction log file with extension .ldf
- The size of the log file (ldf) is determined my the logging level you have set up on the database
- Simple, full, and build logged are the options
- Simple being the least, and full being the most, the logged (if in full) will allow you to re-apply transactions to the database incase of a failure
- If your looking for some performance improvement, there are a lot of things that can be done
.ndf Extension
- .ndf are secondary databse files
- Same as mdf, but you can only have 1 Main database file
- This file also could be stored on a separate physical drive
- Advantage is that, tables that are relatively static are in another file
- Tables that are written frequently are stored in one file
- Having to smaller file to write to for transactions will help with throughput.
Viewing, Renaming and Deleting a Database
Viewing a Database
The information regarding database such as owner, size, date of creation, and status can be viewed using the following:
sp_helpdb database_name
For Example:
sp_helpdb aditya
Renaming Database
The name of database can be changed. The database should not be in use when it is being renamed, and it should be set to the single-user mode.
sp_rename 'old_name','new_name'
where, old_name is the original name of the database
new_name is the new name of datbase
Only system administrator can changed the name of a database.
Deleting a Database
A database is deleted when it is no longer required. Only the system administrator and database owner have permission to delete a database.
DROP DATABASE database_name
where, database_name is the name of the database.
DATA INTEGRITY
There are three most important things when database is accessing:
- Accurate
- Consistent
- Reliable , means its very tuff to maintain data integrity.
Data integrity ensures the consistency and correctness of data stored in a database. It is broadly classified into the following four categories:
Entity Integrity
Entity integrity ensures that each row can be uniquely identified by an attribute called the primary key. The primary key can not be NULL. For example: there might be two candidates for interview with the same name 'alok'. they can be identified using the unique code assigned to them.
Domain Integrity
Domain integrity ensures that only a valid range of values is allowed to be stored in a column. It can be enforced by restricting the type of data, the range of values, and the format of data.
For Example: Let assume that table BranchOffice, that contain various offices of a company and this table has another column city that store the cities where branch offices are located. Assume that offices are located in 'Delhi', 'Mumbai', 'Chanai'. By enforcing the integrity we ensure that only valid values can be entered in the city column of the BranchOffice table.
Referential Integrity
Referential Integrity ensures that the values of the foreign key match with the value of the corresponding primary key.
For Example: In a CollegeStudent table each student has there enrollment number in the column, another table in university database is UniversityStudent which contain Enrollment number that make ensure registration of each student.
User-defined Integrity
User-defined integrity refers to a set by a user, which do not belong to the entity, domain, and referential integrity categories.
For Example: If you want a candidate who is less than 18 years to apply for a post.
CREATING CONSTRAINTS
Constraints can be be enforced at two levels.
- Column level
- Table level
A constraints can be defined on a column at the time of creating a table. It can be created with the CREATE TABLE statement.
1. CREATE TABLE statement:
CREATE TABLE table_name
column_name CONSTRAINTS constraints_name constraints_type [, CONSTRAITS constraints_name constraints_type]
column_name CONSTRAINTS constraints_name constraints_type [, CONSTRAITS constraints_name constraints_type]
where, column_name is the name of the column on which the constraints is to be defined.
constraints_name is the name of the constraints to be created and must follow the rules for the identifier.
constraints_type is the type of constraints to be added.
2. ALTER TABLE statement:
ALTER TABLE table_name
[WITH CHECK or WITH NOCHECK]
ADD CONSTRAINTS constraints_name constraints_type
[WITH CHECK or WITH NOCHECK]
ADD CONSTRAINTS constraints_name constraints_type
where, table_name is the name of the table that is to be altered for adding a constraints.
WITH CHECK and WITH NOCHECK specifies whether the existing data is to be checked or not checked for a newly added constraints or a re-enabled constraints
constraints_name specifies the name of the constraints to be created and must follow the rule for identifier.
constraints_type specifies the type of constraints.
DROPPING CONSTRAINTS
A constraints dropped using the ALTER TABLE statement in the Query Analyzer.
All constraints defined in the table are dropped automatically when the table is dropped.
ALTER TABLE table_name
DROP CONSTRAINTS constraints_name
DROP CONSTRAINTS constraints_name
where, table_name is the name of the table that constraints to be dropped.
constraints_name is the name of the constraints to be dropped.
TYPES OF CONSTRAINTS
[1] PRIMARY KEY constraints
[2] UNIQUE constraints
[3] FOREIGN KEY constraints
[4] CHECK constraints
[5] DEFAULT constraints
[2] UNIQUE constraints
[3] FOREIGN KEY constraints
[4] CHECK constraints
[5] DEFAULT constraints
PRIMARY KEY constraints
A Primary Key constraints is defined on a column whose values uniquely identify rows in a table. These columns are referred to as the primary key columns. A primary key column can not contain NULL values since it is used to uniquely identify rows in a table. the primary key ensure entity integrity.
You can define a PRIMARY KEY constraints at the time of a table creation, or you can add it later by altering the table. While defining a PRIMARY KEY constraints, you need to specify a name for the constraints. If a name is not specified, SQL server automatically assigns a name to the constraints.
CREATE TABLE table_name
(column_name data_type CONSTRAINT constraints_name PRIMARY KEY),..
(column_name data_type CONSTRAINT constraints_name PRIMARY KEY),..
For Example:
CREATE TABLE employee
(emp_name char (4) CONSTRAINT pfemp_name PRIMARY KEY)
(emp_name char (4) CONSTRAINT pfemp_name PRIMARY KEY)
The above command creates a table employee with emp_name as the primary key. The name of the constraints is pfemp_name.
Out Put

Primary key also created after creating a table by following command:
ALTER TABLE employee
ADD CONSTRAINT Pfemp_name PRIMARY KEY (emp_id)
ADD CONSTRAINT Pfemp_name PRIMARY KEY (emp_id)
For Example:

The UNIQUE Constraints
To enforce uniqueness on non-primary columns used the UNIQUE constraints. A primary key constraints column automatically includes a restriction for uniqueness. The unique constraint is similar to the primary key constraint except that it allows NULL values, but there can be only one row in the table with a NULL value. Multiple Unique constraints can be created on a table.
CREATE TABLE table_name
(coloumn_name data_type CONSTRAINT constraint_name UNIQUE)
(coloumn_name data_type CONSTRAINT constraint_name UNIQUE)
For Example:
CREATE TABLE engineer
(eng_name char(4), eng_id char(4) CONSTRAINT uniEng_id UNIQUE)
(eng_name char(4), eng_id char(4) CONSTRAINT uniEng_id UNIQUE)

The above command creates a UNIQUE constraint uniEng_id on the attribute eng_id in the engineer table. The constraints would not allow the duplicate value to be inserted in the uniEng_id attribute. However, there could be one row in the uniEng_id attribute that contains NULL.
We create a UNIQUE constraints after the table has been created by altering the table
ALTER TABLE engineer
ADD CONSTRAINT UNeng_SocialId UNIQUE (eng_SocialId)
ADD CONSTRAINT UNeng_SocialId UNIQUE (eng_SocialId)

The above command creates a UNIQUE constraint UNeng_SocialId on the attribute eng_SocialId in the engineer table.
The Rules regarding to the UNIQUE constraints are:
- It can be created at the column level as well as table level
- It does not allow two rows to have the same non-null value in a table
- Multiple UNIQUE constraints can be placed on a table
The FOREIGN KEY Constraint
- FOREIGN KEY constraint to remove the inconsistency in two tables when data in one table depends on data in another table.
- A FOREIGN KEY constraint associates one or more columns of a table (the foreign key) with an identical set of columns on which a PRIMARY KEY constraint has been defined (a primary key column in another table).
CREATE TABLE table_name
(column_name data_type REFERENCES table_name (emp_id))
(column_name data_type REFERENCES table_name (emp_id))
Syntax:
CONSTRAINT constraint_name FOREIGN KEY (column_name,..)
REFERENCE table_name (column_name,..)
REFERENCE table_name (column_name,..)
For Example:
CREATE TABLE employee
(emp_name char(4), emp_id varchar (16) REFERENCES engineer (emp_id))
(emp_name char(4), emp_id varchar (16) REFERENCES engineer (emp_id))
The above command creates a FOREIGN KEY on the attribute emp_id of the employee table that reference the primary key emp_id of the engineer table. This will ensure that the employeeID code that is inserted into the employee table is checked against the engineer table for the validity.

If the employee table is exist and does not have foreign key defined, then table also modified using ALTER TABLE command.
ALTER TABLE employee
ADD CONSTRAINT fkemp_id FOREIGN KEY (emp_id) REFERENCES engineer (emp_id)

The CHECK Constraint
A check constraint:
- Enforces the domain integrity by restricting the values to be inserted in a column
- Constraints are evaluated in the order in which they are defined
- There is a possible to define multiple CHECK constraints on a single column
- If check constraints defined at the table level it can be applied for the multiple columns
Syntax:
[CONSTRAINT constraint_name ] CHECK (expression)
where, constraint_name specifies the name of the constraint to be created.
expression specifies the conditions that define the check to be made on the column. It can be any expression arithmetic operation, relational operation or keywords :
1. The IN keyword.
2. The LIKE keyword.
3. The BETWEEN keyword.
2. The LIKE keyword.
3. The BETWEEN keyword.
The rules regarding the creation of the CHECK constraint are as follows:
- It can be created at the column level
- It can be contain user-specified search condition
- It cannot contain sub queries
- It does not check the existing data in the table if created with the WITH NOCHECK option
- It can reference other columns of the same table
Using Logical Operator
Multiple search condition done by using logical operator. They are:
1. OR: Any of the specified search condition is true.
SELECT column_list
FROM table_name
WHERE condition_expression OR condition_expression
FROM table_name
WHERE condition_expression OR condition_expression
Return all rows specific to the conditions, even if any one of the condition is true.
2. AND: When all specified search conditions are true.
SELECT column_list
FROM table_name
WHERE condition_expression AND condition_expression
FROM table_name
WHERE condition_expression AND condition_expression
Return all rows specific to the conditions, when both conditions are true.
3. NOT: Neutralizes the expression that follow it.
SELECT column_list
FROM table_name
WHERE condition_expression {OR/AND} NOT condition_expression
FROM table_name
WHERE condition_expression {OR/AND} NOT condition_expression
Return all rows specific to the conditions, except the rows that match the condition specified after the NOT operatoor.
Using List Operator
SQl provides IN and NOT IN operators. IN operator that allowed the selection of values that match any one of the values in a list. NOT IN operator restrict the selection of values that match any one of the values in a list.
SELECT column_list
FROM table_name
WHERE condition list_operator('value_list')
FROM table_name
WHERE condition list_operator('value_list')
list_operator is any valid list operator.
value_list is the list of values to be included or excluded in the condition
For Example:
SELECT *
FROM publishers
WHERE state IN ('MA','DC')
FROM publishers
WHERE state IN ('MA','DC')
SELECT *
FROM publishers
WHERE state NOT IN ('MA','DC')
FROM publishers
WHERE state NOT IN ('MA','DC')
Using String Operator
String operator provide a LIKE keyword to search for a string with wild card mechanism.
Wildcard
|
Description
|
| % | Represents any string of Zero or more character |
| _ | Represent the single character |
| [] | Represent any single character within the specified range |
| [^] | Represent any single character not within the specified range |
For Example:
SELECT *
FROM titles
WHERE type LIKE 'bus%'
FROM titles
WHERE type LIKE 'bus%'
Return all attribute from the titles table in which the type starts with 'bus'
SELECT *
FROM titles
WHERE type LIKE 'bu_'
FROM titles
WHERE type LIKE 'bu_'
Return all attribute from the titles table in which the type of book is the three character long and starts with 'bu'. Increase the '_' keyword increase the number of characters.
SELECT *
FROM titles
WHERE type LIKE 'b[us]%'
FROM titles
WHERE type LIKE 'b[us]%'
Return all attribute from the titles table in which the type of book is starts with 'b' and contain u and s on the second position followed by any number of character.
SELECT *
FROM titles
WHERE type LIKE 'b[^s]%'
FROM titles
WHERE type LIKE 'b[^s]%'
Return all attribute from the titles table in which the type of book is starts with 'b' and does not contain s on the second position followed by any number of character.
Some Examples
Expression
|
Returns
|
| LIKE '%ty%' | All names that have the letters 'ty' in them |
| LIKE '_ty' | All three letter names ending with 'ty' |
| LIKE '[AD]%' | All name that begin with "A" or "K" |
Using Comparison Operators
Comparison operator allow row retrieval from a table based on the condition specified in the WHERE clause.
SELECT column_list
FROM table_name
WHERE expression1 comparison_operator expression2
FROM table_name
WHERE expression1 comparison_operator expression2
Operator
|
Description
|
| = | Equal to |
| > | Greater than |
| < | Less than |
| >= | Greater than or equal to |
| <= | Less than or equal to |
| <>,!= | Not equal to |
| !> | Not greater than |
| !< | Not less than |
| () | Controls precedence |
For Example:
SELECT pub_id
FROM publishers
WHERE city='Boston'
FROM publishers
WHERE city='Boston'
Using Range Operators
The range operator is used to retrieve data between range . The range operator are:
1. BETWEEN: Specified an inclusive range to search.
SELECT column_list
FROM table_name
WHERE expression1 BETWEEN expression1 AND expression1
FROM table_name
WHERE expression1 BETWEEN expression1 AND expression1
For Example: Below query return the attribute list value between 2000 and 5000
SELECT *
FROM titles
WHERE advance BETWEEN 2000 AND 5000
FROM titles
WHERE advance BETWEEN 2000 AND 5000
2. NOT BETWEEN: This key word used to exclude the rows from the specified range in the result set.
SELECT column_list
FROM table_name
WHERE expression1 NOT BETWEEN expression1 AND expression1
FROM table_name
WHERE expression1 NOT BETWEEN expression1 AND expression1
For Example: Below query return the attribute list value which not between 2000 and 5000
SELECT *
FROM titles
WHERE advance NOT BETWEEN 2000 AND 5000
FROM titles
WHERE advance NOT BETWEEN 2000 AND 5000
The DEFAULT Constraint
A default constraint can be used to assign a constant value to a column, and the user need not insert values for such a column . Only one DEFAULT constraint values can be created for a column , but the column cannot be an IDENTITY column. The system-supplied values like USER, CURRENT_USER, and user defined values can be assigned as defaults.
CREATE TABLE table_name
(column_name data_type DEFAULT [constant_expression])
(column_name data_type DEFAULT [constant_expression])
where, constraint_name specifies the name of the constraint to be created.
constant_expression specifies an expression that contains only constant values and can contain NULL.
For Example:
CREATE TABLE employee
(cCity char (14) DEFAULT 'New Delhi', emp_id varchar(15))
(cCity char (14) DEFAULT 'New Delhi', emp_id varchar(15))
The above command use to create a DEFAULT constraint on the cCity attribute. If a city is not specified, then the cCity attribute would contain 'New Delhi' by default.

If table already created then using ALTER command we specified the DEFAULT constraint
ALTER TABLE employee
ADD CONSTRAINT defcCity DEFAULT 'New Delhi' FOR cCity
ADD CONSTRAINT defcCity DEFAULT 'New Delhi' FOR cCity

INDEXES
An Indexes is:
- SQL server used an internal table structure that provide quick access to rows of a table
- It is totally based on the values of one or more columns
- SQL Server indexes are like the indexes at the back of a book, which help in locating content
Advantage Of Using Indexes
- The primary purpose of an index is to provide faster access to data pages
- When server searched anything, it searching the index at the place of searching the whole page
- Server scan the index and get the address of data storage location and directly access the information
- Indexes are also used as a mechanism of enforcing data uniqueness
- An index speeds up the processing of queries that use joins or other clauses like ORDER BY or GROUP BY, by allowing to faster access of data
- Improve the speed of the execution of queries
- Enforce uniqueness of data
- Speed up joins between table
Disadvantage Of Using Indexes
- Indexes does not indexing every column of the table
- It takes time to create index
- Each index create requires space to store data along with the original data source-the table
- An index gets updated each time the data is modified
Types Of INDEXES
There are two types of indexes:
- CLUSTERED Index
- NONCLUSTERED Index
CLUSTERED INDEX
- The data is physically stored
- There is only one clustered index can be created per table
- Clustered index must be build on attribute that have a high percentage of unique values and they are not modified often
- A clustered indexes should be created before a nonclustered index
- A clustered index changes the order of the rows.
How Clustered Indexes Work
In clustered index data are stored at the leaf level of the B-tree. The data pages of a table are like folders stored in an alphabetically order in the filling cabinet, and the rows of the data are like the documents stored in folders.
SQL server performs the following steps when it uses a clustered index to search for a value:
Step 1. First SQL sever find the root page from the sysindexes table
Step 2. The search value is compared with the key values on the root page
Step 3. The page with the highest key value less than or equal to the search value is found
Step 4. The page pointer is followed the next lower level in the index
Step 5. Step 3 and 4 repeated until the data page is reached
Step 6. The rows of the data are searched on the data page until the search value is found. If the search value is not found on the data page, no rows are returned by the query
Example: Consider the following example in which the rows of the employee table are sorted according to the Eid attribute and stored in the table.

If the row containing Eid E006 were to be searched using the clustered index displayed in the figure, the following step will be followed.
- SQL Server starts from page 603, the root page
- It searches the highest key value on the page, which is less than or equal to the search value. The result of this search is the page containing the pointer to Eid E005
- The search continues from page 602
- There, the Eid E005 is found and the search continues on page 203
- Page 203 is searched to find the required row
NONCLUSTERED INDEX
- The physical order of the rows is not the same as the index order
- Nonclustered indexes are typically created on columns used in joins and WHERE clauses, and whose values may be modified frequently
- SQL server creates nonclustered indexes by default when the CREATE INDEX command is given
- There can be as many as 249 nonclustered indexes per table
- Typically, nonclustered indexes are created on foreign keys
- A nonclustered index would need to be rebuilt if it is built before a clustered index
How Nonclustered Indexes Work
Step 1. First SQL sever find the root page from the sysindexes table.
Step 2. The search value is compared with the key values on the root page.
Step 3. The page with the highest key value less than or equal to the search value is found.
Step 4. The page pointer is followed the next lower level in the index.
Step 5. Step 3 and 4 repeated until the data page is reached.
Step 6. The rows are searched on the leaf page for the specified value. if a matched is not found, the table contains no matching rows.
Step 7. If a match is found, the pointer is followed to the data page and row-ID in the table, and the requested row is retrieved.
Example: If the row containing Eid E006 were to be searched using the nonclustered index displayed in the figure, the following steps would be followed:
- SQL Server starts from page 603, the root page
- It searches the highest key value on the page, the page with a key value less than or equal to the search value, that is, to the page containing the pointer to Eid E005
- The search continues from page 602
- There, the Eid E005 is found and the search continues on page 203
- Page 203 is searched to find a pointer to the actual row. Page 203 is the last, or the leaf page of the index
- The search then moves to page 302 of the table to find the actual row

How to Create an INDEX
1. Identify the tables on which the index will be created.
2. Identify the attribute on which the index will be created.
3. Identify the type of index will be created.
4. Identify the name of the index to be created. (Prefix an 'idx' to the name of the index to help in locating/identifying the index.)
5. Create the index.
Syntax:
CREATE [UNIQUE] [CLUSTERED or UNCLUSTERED] INDEX index_name
ON table_name (column_name...)
ON table_name (column_name...)
where, UNIQUE creates an index in which each row should contain a different index value.
CLUSTERED specifies a clustered index in which data is sorted on the index attribute.
NONCLUSTERED specifies a nonclustered index that organizes data only logically. the data is not sorted physically.
index_name specifies the name of the index.
The index name should be unique in the table, but it may not be unique within a database.
table_name specifies the name of table and column_name is the name of columns on which the index would be created.
CREATE CLUSTERED INDEX ad_name
ON employee (emp_id)
ON employee (emp_id)

How to Verify that Indexes has been created
Syntax:
sp_helpindex table_name
CREATE NONCLUSTERED INDEX INemp_name
ON employee (emp_name)
ON employee (emp_name)
sp_helpindex employee
Out Put:
Programming in SQL Server
- Batches
- Variables
- Printing Messages
- Comments
- Control-of-flow statements
Batches
- Batches are groups of SQL statement submitted together to SQL Server for execution
- A batch is parsed
- A batch is optimized
- A batch is compiled
- A batch is executed
- SQL server compiled the statements of a batch into a single unit called an execution plane
- The statement in the execution plane are then executed one at a time
- There is any error in a batch, no statement in the batch is executed
Restriction
- You cannot bind rules and defaults to columns and use them in the same batch
- You can not define and use the CHECK constraints in the same batch
- You can not drop object and recreate them in the same batch
- you cannot alter a table and reference the new column in the same batch
Variables
Variable used to store a temporary value. We can declare and assign a value to a variable, declared a variable by using DECLARE statement.
Syntax: DECLARE @variable_name data_type
The @ symbol before the variable name. This symbol is required and is used by the query processor to identify variable.
For Exaple:
DECLARE @empID int
SELECT @empID=max(emp_id)
FROM employee
SELECT new_empID=@empID
FROM employee
SELECT new_empID=@empID
In the first line DECLARE keyword declare a variable empID of int type, and in second line the maximum value of emp_id attributes from employee table stored in the empID variable
Out Put: The output will be

Global Variables: Global variable are system-supplied and predefined. These variables are distinguished from local variables by having two @ signs preceding their names
Variable name
|
Returns
|
| @@ version | Date, version and other information on the current version |
| @@ servername | Name of SQL server |
| @@ spid | Server process id number of the current process |
| @@ procid | Stored process ID of the current-executing procedure |
| @@ error | 0 if the last transaction succeeded, otherwise the last error number |
| @@ rowcount | Number of rows affected by the last query, 0 if no rows are affected |
| @@ connection | Sum of the number of connections and the attempted connections since Microsoft server was started |
| @@ trancount | Number of currently-active transactions for a user |
| @@ max_connections | Maximum number of simultaneous connections |
| @@ total_errors | Total number of errors that have occurred during the current SQL server session |
SELECT servername='Name=' + @@servername

Printing Messages
PRINT statement display the user defined message or the content of a variable on the screen
For Example:
DECLARE @Name char(15)
SELECT @Name='Anil Yadav'
PRINT @Name
SELECT @Name='Anil Yadav'
PRINT @Name
Out Put:
Anil Yadav
For Example:
DECLARE @empID int
SELECT @empID=max(emp_id)
FROM employee
PRINT @empID
SELECT @empID=max(emp_id)
FROM employee
PRINT @empID
Out Put:
12348
Comment Entry
- Comment entries are used to write the description of code in batches
- This will help to read the description of code
- Multiple line comment entries enclosed within /* and */
- Single line comment entry starting with --(double hyphens)
Control-of-Flow Language
The control -of -flow language controls the flow of execution of SQL statement in batches, stored procedures, triggers, and transactions. It is typically used when statements have to be conditionally or repeatedly executed. The control -of -flow language transforms standard SQL into a programming language.
The control -of -flow statements provided by SQL server :
1. The IF...ELSE statement
2. The CASE statement
3. The WHILE statement
The IF...ELSE Statement and BEGIN...END Statement
IF...ELSE Statement
Syntax:
IF boolean_expression
{sql_statement}
ELSE boolean_expression
{sql_statement}
{sql_statement}
ELSE boolean_expression
{sql_statement}
where, boolean_expression is the condition that evaluates to either TRUE or FALSE.
sql_statement is any T-SQL statement.
statement_block is a collection of T-SQL statements.
BEGIN...END Statement
Syntax:
BEGIN
{sql_statement}
END
{sql_statement}
END
where, sql_statement is one or more SQL statements
The BEGIN...END block is nested and is most often used with the IF...ELSE statement and the WHILE looops.
Example:
IF EXISTS (SELECT * FROM employee WHERE emp_name='anchal')
BEGIN
PRINT 'The Details of employee are Available'
SELECT * FROM employee WHERE emp_name='anchal'
END
ELSE
PRINT 'Employee details not Available'
BEGIN
PRINT 'The Details of employee are Available'
SELECT * FROM employee WHERE emp_name='anchal'
END
ELSE
PRINT 'Employee details not Available'
Out Put: anchal related information viewed
IF EXISTS (SELECT * FROM employee WHERE emp_name='anchal')
BEGIN
PRINT 'The Details of employee are Available'
SELECT * FROM employee WHERE emp_name='Ram'
END
ELSE
PRINT 'Employee details not Available'
BEGIN
PRINT 'The Details of employee are Available'
SELECT * FROM employee WHERE emp_name='Ram'
END
ELSE
PRINT 'Employee details not Available'
Out Put:
There is no information shown related to Ram
For Example: There are number of employee in the employee table and there salary different according to there experience, the administrator want to increase there salary then this code be written.
SELECT * FROM employee

IF (SELECT MAX (emp_sal) FROM employee )<45000
BEGIN
UPDATE employee
SET emp_sal=emp_sal+25000
END
ELSE
BEGIN
UPDATE employee
SET emp_sal=emp_sal+10000
END
BEGIN
UPDATE employee
SET emp_sal=emp_sal+25000
END
ELSE
BEGIN
UPDATE employee
SET emp_sal=emp_sal+10000
END
SELECT * FROM employee
The CASE Statement
- SQL server provide a programming construct called CASE statement
- In this situation where several conditions need to be evaluated
- The CASE statement evaluate a list of conditions and return one of the various possible results
- Here we can use IF statement to do same task
Syntax:
CASE
WHEN boolean_expression THEN expression
[[WHEN boolean_expression THEN expression]..]
[ELSE expression]
END
WHEN boolean_expression THEN expression
[[WHEN boolean_expression THEN expression]..]
[ELSE expression]
END
where, boolean_expression is a Boolean expression that is evaluated when using the CASE statement.
For Example: Give the position according to there Salary.
SELECT emp_name, emp_sal, 'emp_position'= CASE
WHEN emp_sal=60000 THEN 'Team Leader'
WHEN emp_sal=45000 THEN 'Junior Developer'
WHEN emp_sal=80000 THEN 'Project Manager'
WHEN emp_sal=50000 THEN 'Developer'
ELSE 'Unknown'
END
FROM employee
WHEN emp_sal=60000 THEN 'Team Leader'
WHEN emp_sal=45000 THEN 'Junior Developer'
WHEN emp_sal=80000 THEN 'Project Manager'
WHEN emp_sal=50000 THEN 'Developer'
ELSE 'Unknown'
END
FROM employee
Out Put:

The WHILE Statement
- While statement is used in a batch, a stored procedure, a trigger, or a cursor
- Its allowed a set of T-SQL statements to execute repeatedly as long as the given condition hold true
Syntax:
WHILE boolean_expression
{sql_statement}
[BREAK]
{sql_statement}
[CONTINUE]
{sql_statement}
[BREAK]
{sql_statement}
[CONTINUE]
where, boolean_expression is an expression that evaluate to TRUE or FALSE.
sql_statement is any SQL statement.
BREAK cause the control to exit from the WHILE loop.
CONTINUE cause the WHILE loop to restart, skipping all the statements after the CONTINUE keyword.
SQL Server provides the BREAK and CONTINUE statements that help control the statements within the WHILE loop.
For Example: Factorial of 5
DECLARE @num int
DECLARE @fact int
SELECT @num=5
SELECT @fact=1
WHILE @num>0
BEGIN
SELECT @fact=@fact*@num
SELECT @num=@num-1
END
PRINT @fact
DECLARE @fact int
SELECT @num=5
SELECT @fact=1
WHILE @num>0
BEGIN
SELECT @fact=@fact*@num
SELECT @num=@num-1
END
PRINT @fact
Out Put:
120
STORED PROCEDURES
SQL server is based on Client/Server technology. A number of clients send queries to the central server. After receiving the query, the server parses the query and check the syntaxes errors. After this processes the request. The query passes through the network , its add the network congestion and increased the traffic. A stored procedure is a solution to these problems. It can be created through the Enterprise Manager or using the Query Analyzer window with the CREATE PROCEDURE statement. "A Stored Procedure is a precompiled object stored in the database."
Benefits Of Stored Procedure
- Improved performance: SQL server does not have to compile the procedure repeatedly
- Reduction in network congestion: Application need not submit multiple T-SQL statement to the server for the purpose of processing
- Better Consistency: The coding logic and T-SQL statements defined in the procedure are uniformly implemented across all applications as the procedure serves as a single point of control
- Better security mechanism: Users can be granted permission to execute a stored procedure even if they do not own the procedure
Types Of Procedures
- User Defined Stored procedure: The user defined stored procedures are created by users and stored in the current database
- System Stored Procedure: The system stored procedure have names prefixed with sp_. Its manage SQL Server through administrative tasks. Which databases store system stored procedures are master and msdb database
- Temporary Stored procedures: The temporary stored procedures have names prefixed with the # symbol. Temporary stored procedures stored in the tempdb databases. These procedures are automatically dropped when the connection terminates between client and server
- Remote Stored Procedures: The remote stored procedures are procedures that are created and stored in databases on remote servers. These remote procedures can be accessed from various servers, provided the users have the appropriate permission
- Extended Stored Procedures: These are Dynamic-link libraries (DLL's) that are executed outside the SQL Server environment. They are identified by the prefix xp_
How To Create Stored Procedure
The CREATE PROCEDURE statement
Guideline
- Identify the database in which the stored procedure has to be created
- Determine the type of stored procedure
- Determine the name for the stored procedure
- Write the batch statement
Syntax
CREATE PROCEDURE proc_name
AS
BEGIN
sql-statement 1
sql-statement 1
END
AS
BEGIN
sql-statement 1
sql-statement 1
END
where, proc_name specifies the name of the stored procedure.
For Example
CREATE PROCEDURE empNameList
AS
BEGIN
SELECT 'Employee'=emp_name, 'Salary'=emp_sal
FROM employee
END
AS
BEGIN
SELECT 'Employee'=emp_name, 'Salary'=emp_sal
FROM employee
END
Stored Procedure Created.
Check the existence of the procedure in the database
Syntax
sp_helptext proc_name
sp_helptext empNameList
Out Put

Execute the procedure
Syntax
EXECUTE proc_name
EXECUTE empNameList
Out Put

No comments:
Post a Comment